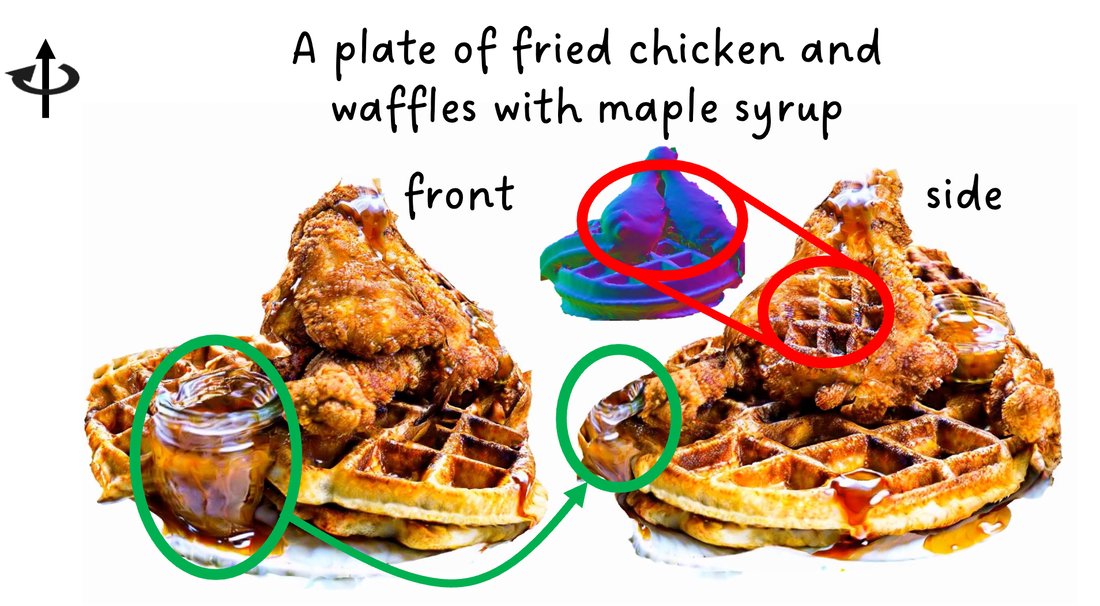
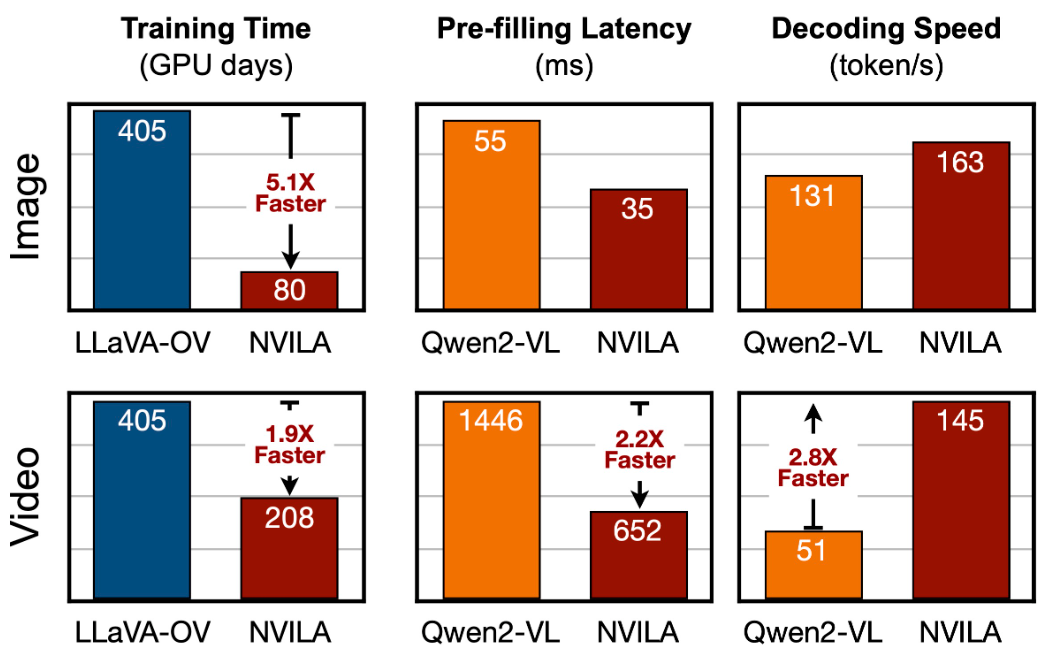
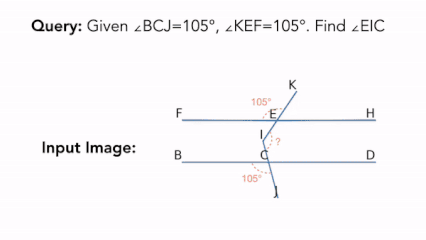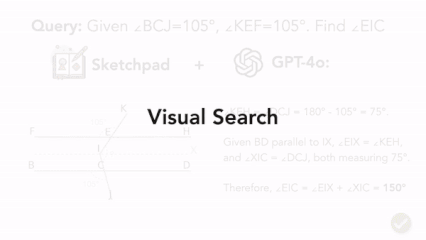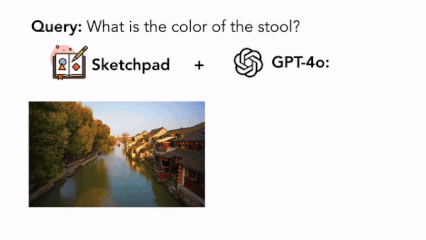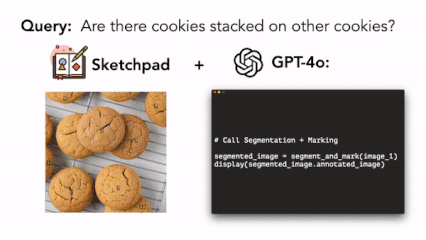
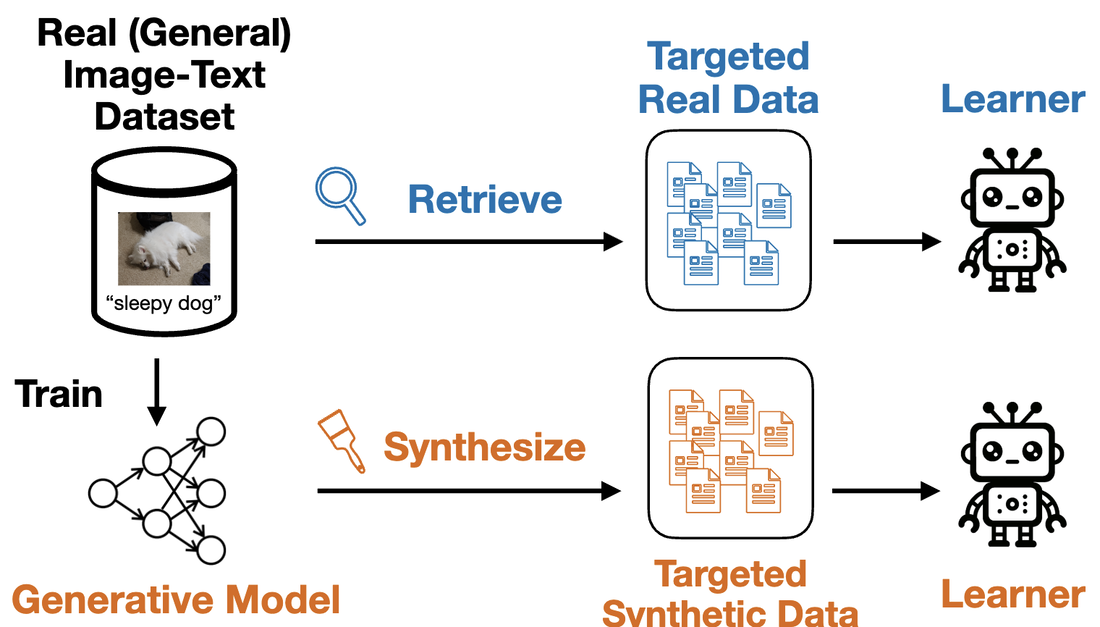
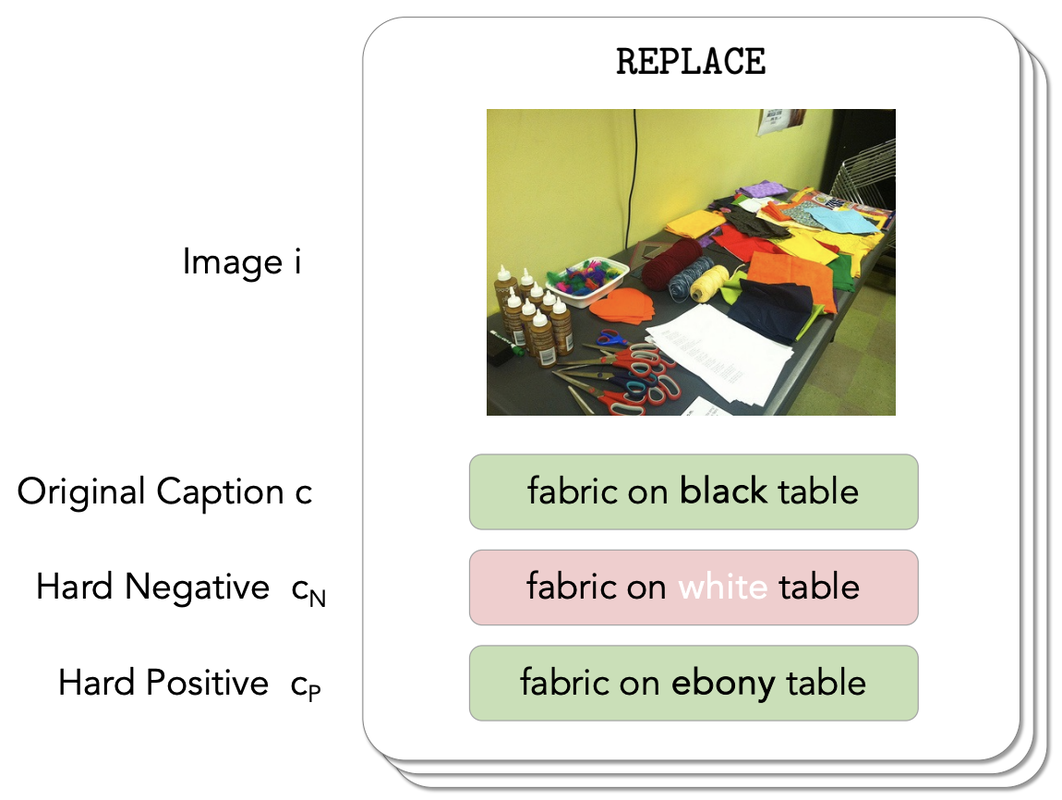
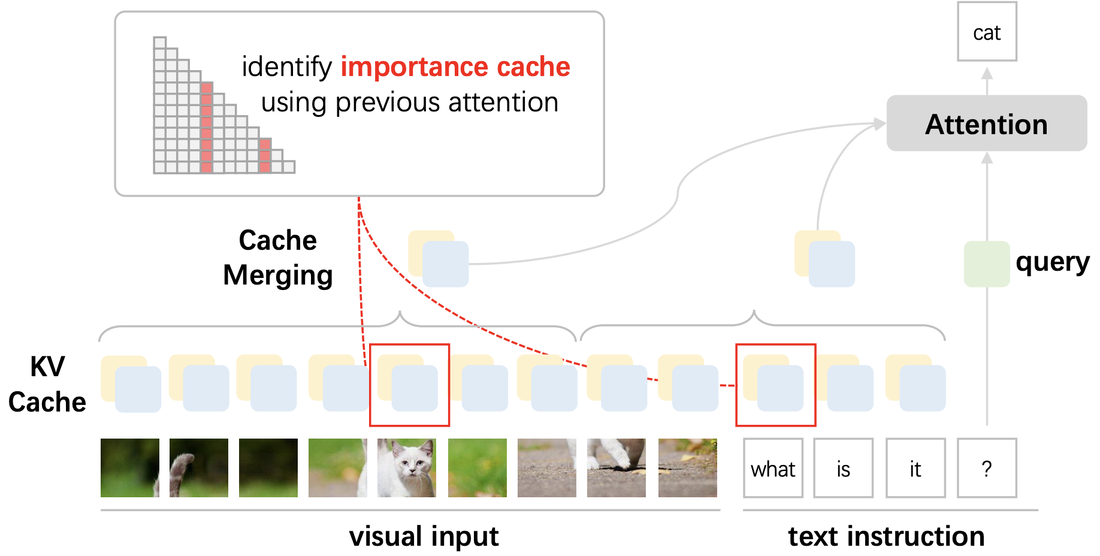
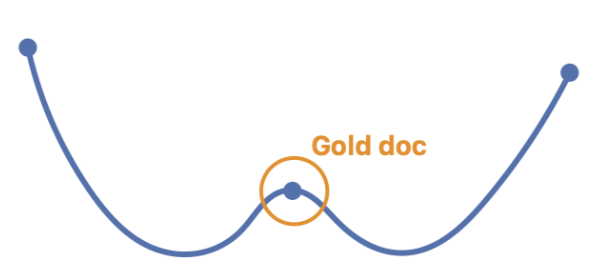
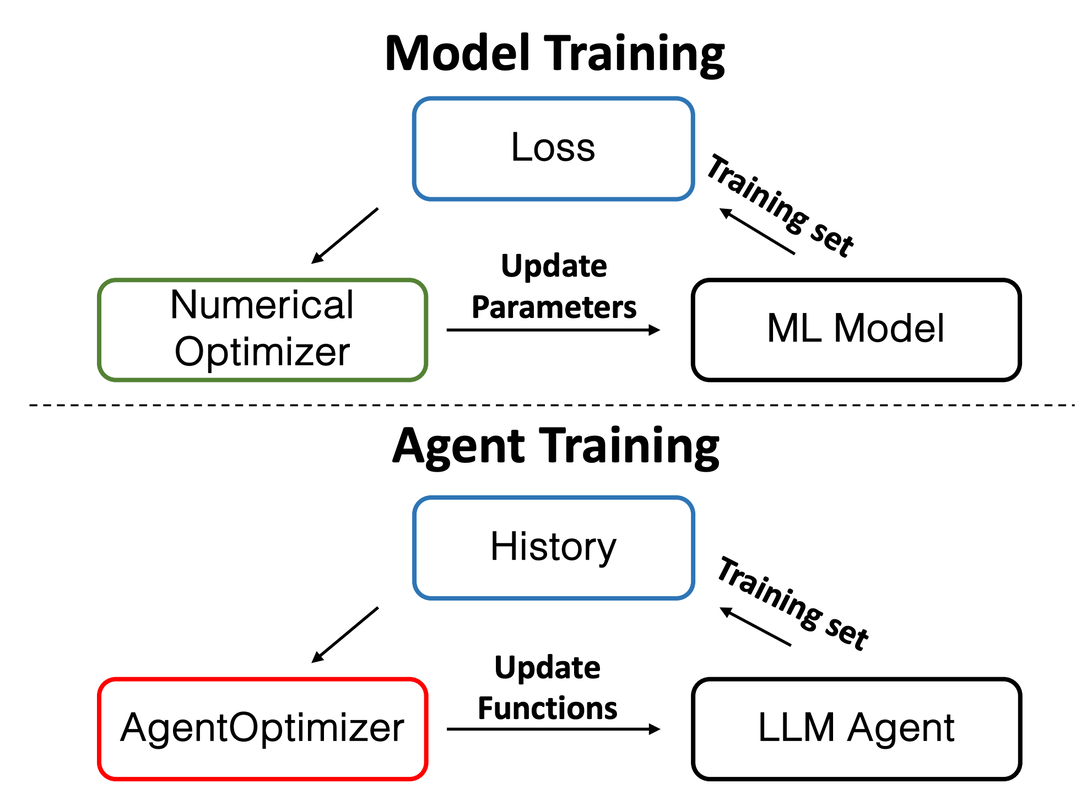
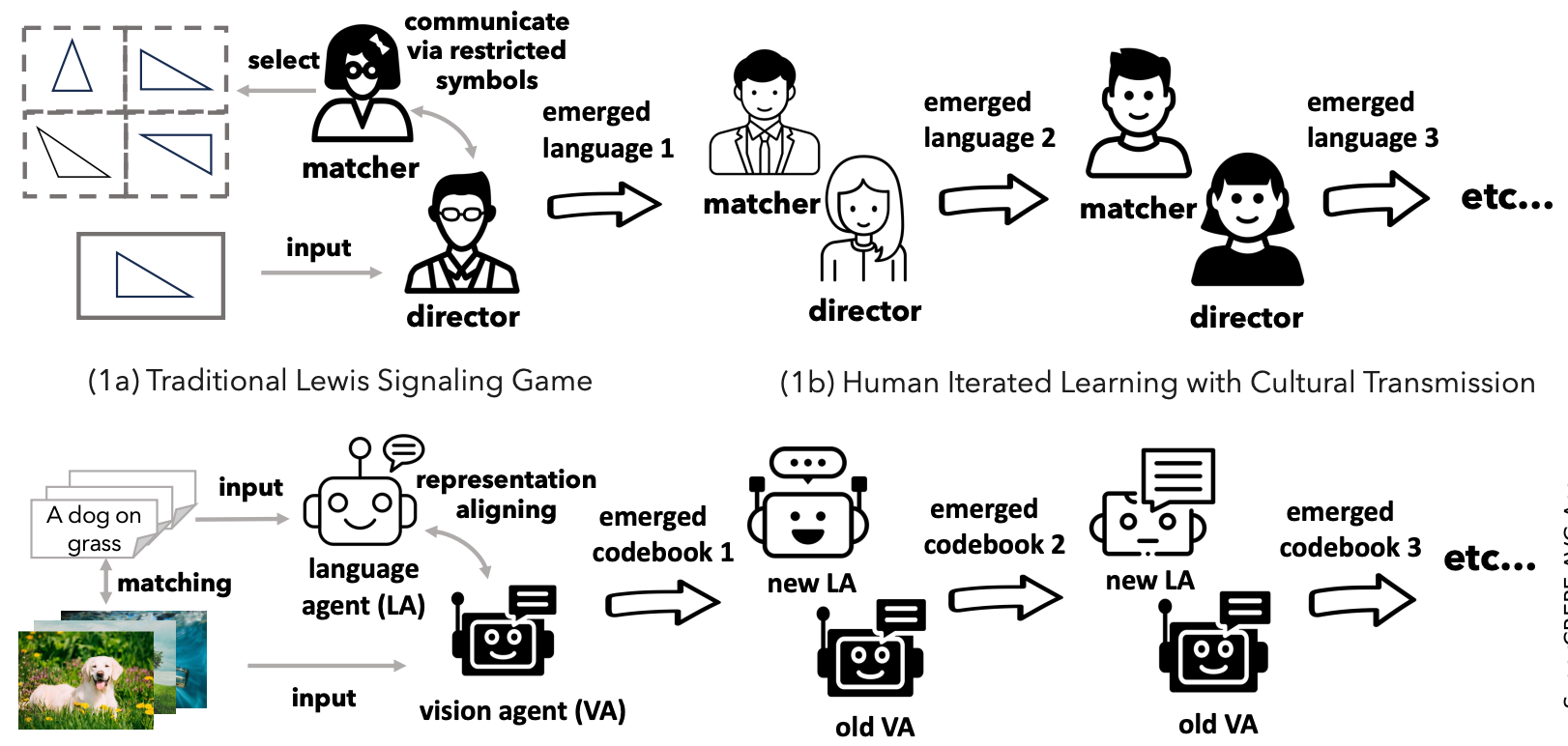
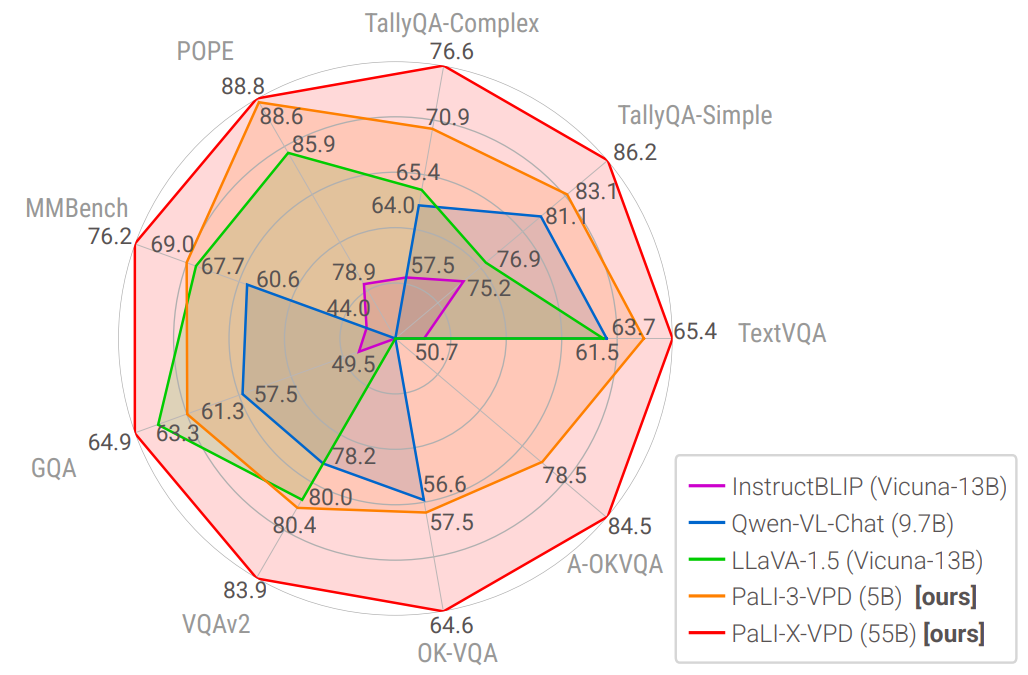
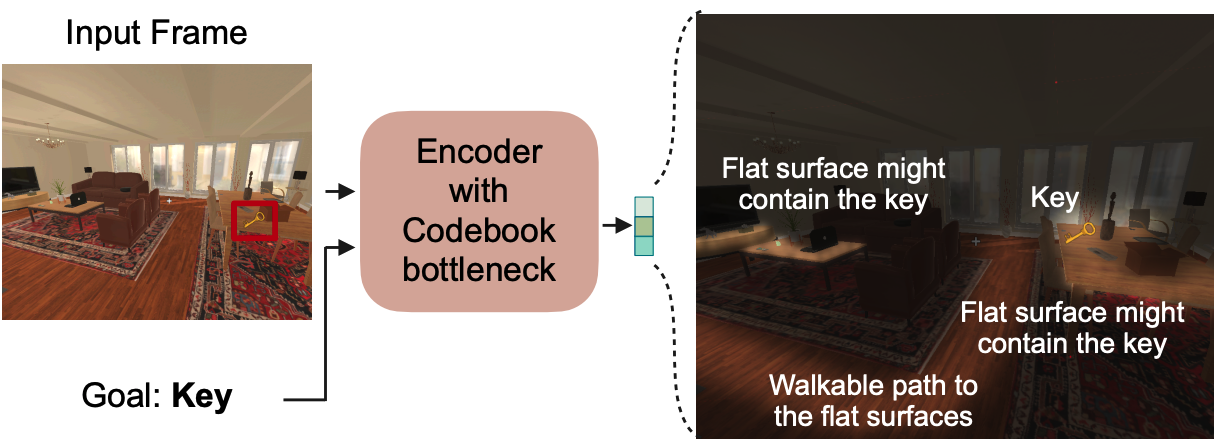
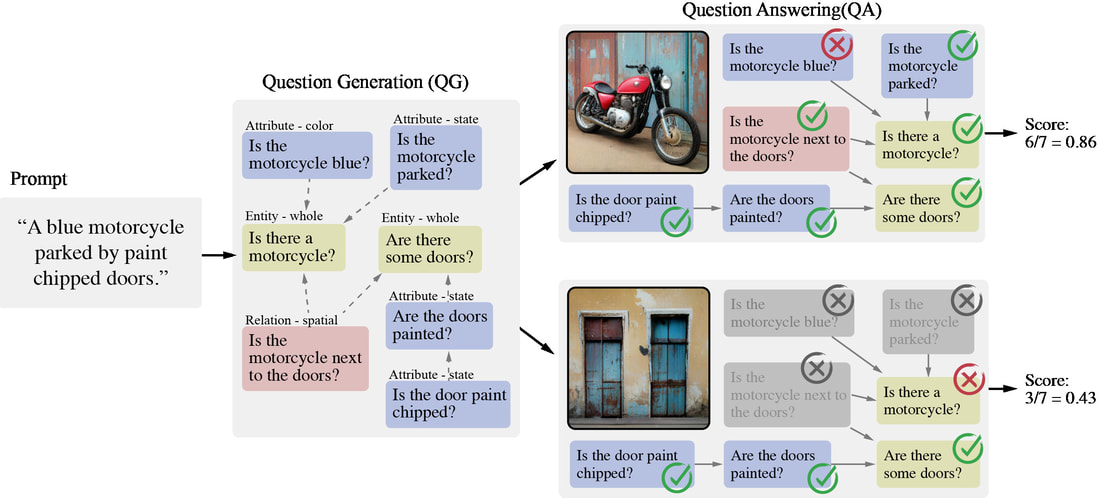
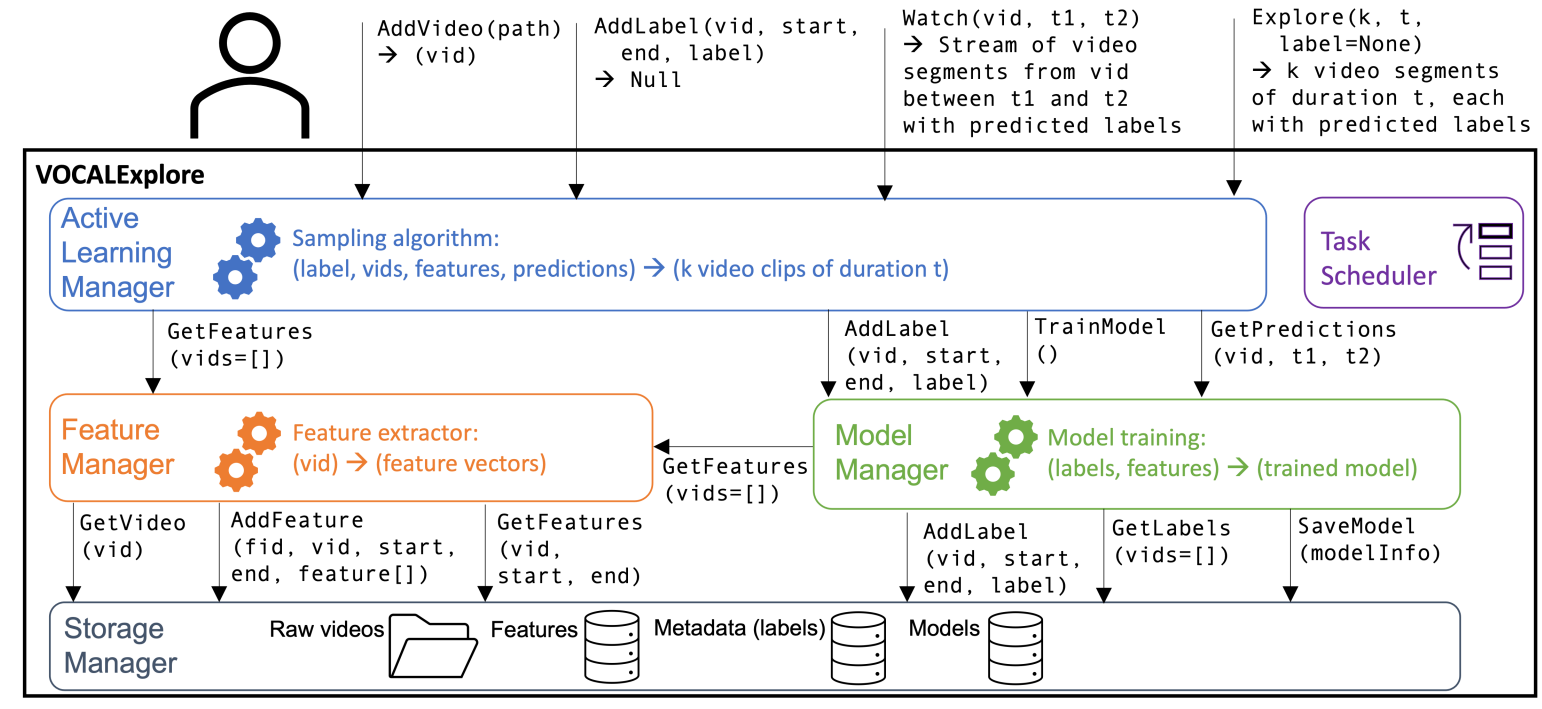
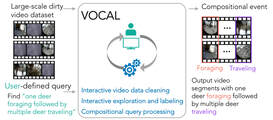
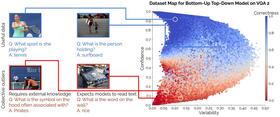
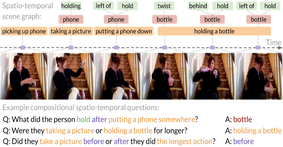
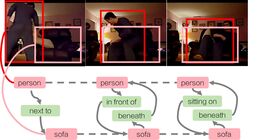
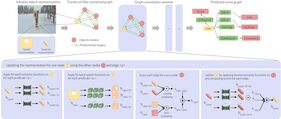
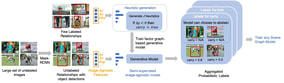
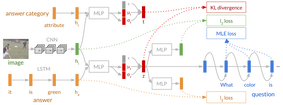
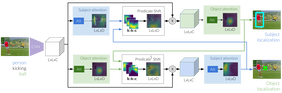
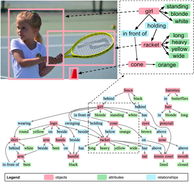
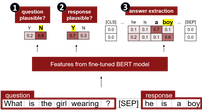
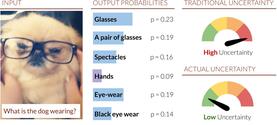
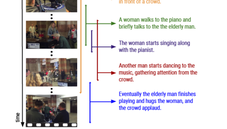
|
I teach machines to see like people and interact with people. As modern machines struggle to fully conceptualize the visual world, my research bootstraps machine learning using frameworks from behavioral and social sciences.
Ranjay Krishna is an Assistant Professor at the Paul G. Allen School of Computer Science & Engineering. He co-directs the RAIVN lab at UW and leads the computer vision team at Ai2. His research lies at the intersection of computer vision, natural language processing, robotics, and human computer interaction. This research has received best paper, outstanding paper, and orals at CVPR, ACL, CSCW, NeurIPS, UIST, and ECCV, and has been reported by Science, Forbes, the Wall Street Journal, and PBS NOVA. His research has been supported by Google, Apple, Ai2, Amazon, Cisco, Toyota Motor Inc, Toyota Research Institute, NSF, ONR, and Yahoo. He holds a bachelor's degree in Electrical & Computer Engineering and in Computer Science from Cornell University, a master's degree in Computer Science from Stanford University and a Ph.D. in Computer Science from Stanford University. RECENT PAPER HIGHLIGHTS
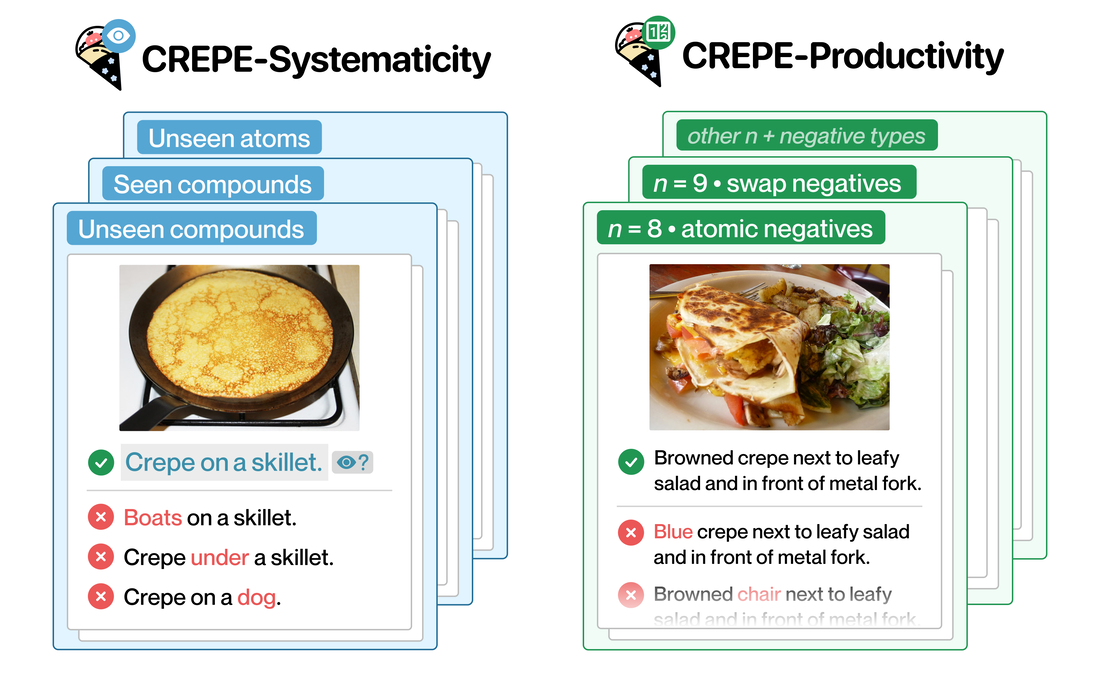
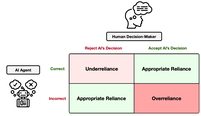
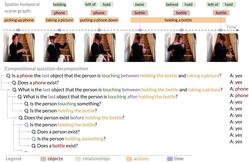
[Jun 2025] Our Molmo paper received Best Paper Honorable Mention at CVPR 2025. [Jun 2025] Our Molmo paper will appear as a Oral at CVPR 2025, awarded to top 0.7% of submissions. [Apr 2025] Our interleaved scene graph paper will appear as a Spotlight at ICLR 2025, awarded to top 5% of submissions [Dec 2024] Our Multilingual diversity for LLMs paper will appear as an Spotlist at NeurIPS 2024, awarded to top 5% of submissions. [June 2024] Our Visual Program Distillation paper will appear as an Oral at CVPR 2024, awarded to top 5% of submissions. [May 2024] Our Selective Visual Representations paper will appear as a Spotlight at ICLR 2024, awarded to top 5% of submissions. [Dec 2023] Our DataComp paper will appear as an Oral at NeurIPS 2023, awarded to top (0.6%) submissions. [Dec 2023] Our Quilt-1M will appear as an Oral at NeurIPS 2023, awarded to top (0.6%) submissions. [Oct 2023] Our paper on Explanations and human-AI decision making got awarded a Best Paper Honorable Mention at CSCW 2023 [Mar 2023] Our CREPE paper was recognized as a Highlight at CVPR 2023, awarded to top 2.5% of submissions. RECENT TALKS @ CONFERENCES [Jul 2025] Invited talk at CogSci 2025 workshop on Minds in the Making [Jun 2025] Keynote at CVPR 2025 workshop on Harnessing Generative Models for Synthetic Visual Datasets [Jun 2025] Keynote at CVPR 2025 workshop on Generalization in Robotics Manipulation [Jun 2025] Keynote at CVPR 2025 workshop on 3D Vision Language Models for Robotic Manipulation [Jun 2025] Keynote at CVPR 2025 workshop on Demographic Diversity in Computer Vision [Mar 2025] Invited talk at RAISE 2025 seminar series at the University of Washington [Dec 2024] Invited talk at IndoML 2024 Symposium [Dec 2024] Keynote at NeurIPS 2024 workshop on Multimodal Algorithmic Reasoning [Oct 2024] Keynote at ECCV 2024 workshop on Efficient Deep Learning for Foundation Models [Oct 2024] Keynote at ECCV 2024 workshop on Green Foundation Models [Jun 2024] Invited talk at DUB 2024 speaker series at the University of Washington [Jun 2024] Keynote at CVPR 2024 workshop on Evaluation of Generative Foundation Models [Jun 2024] Keynote at CVPR 2024 workshop on Computer Vision with Humans in the Loop [April 2023] Invited DUB seminar talk at the University of Washington [Oct 2023] Keynote at ICCV 2023 workshop on Scene Graphs and Graph Representation Learning [Oct 2023] Keynote at ICCV 2023 workshop on On Closing The Loop Between vision an language [Aug 2023] Distinguished researcher talk on Compositionally at Salesforce AI [July 2023] Talk on Embodied Intelligence at the AAAI 2023 Inaugural Summer Symposium on Embodied Intelligence [Jun 2023] Keynote at CVPR 2023 workshop on New Frontiers in Vision and Language Reasoning. RECENT WORKSHOPS [Jun 2025] Synthetic Data for Computer Vision at CVPR 2025 [Jun 2024] Synthetic Data for Computer Vision at CVPR 2024 [Oct 2023] International Challenge on Compositional and Multimodal Perception at ICCV 2023 [Jul 2023] Artificial Intelligence and Human-Computer Interaction at ICML 2023 ACademic Publications
2024
2023
2022
EARLIER PUBLICATIONS
Non-Archival PAPERS
|

Ph.D. @ Stanford University, 2021
Co-advised by Fei-Fei Li and Michael Bernstein. Curriculum Vitae [2024] Google scholar Research statement [2021] Teaching statement [2021] Diversity statement [2021] CONTACT
ranjay [at] cs [dot] washington [dot] edu Bill & Melinda Gates Center Room 304 3800 E Stevens Way NE, Seattle, WA 98195 TEACHING
University of Washington: CSE 599H: AI vs IA [2023] CSE 493G1: Deep learning [2025] [2024] [2023] CSE 455: Computer Vision [2025] [2024] Stanford University: CS231N: Convolutional Neural Networks for Visual Recognition [2021] [2020] CS131 Computer Vision: Foundations and Applications [2019] [2018] [2017] [crowdsourced class notes] RESEARCH GROUPPhD students

Cheng-Yu Hsieh
(2020-) 
Jieyu Zhang
(2020-) 

Benlin Liu
(2021-) 







Xiang Fan
(2023-) 
Linjie Li with Yejin Choi
(2023-) 
Chenhao Zheng
(2024-) Masters and undergraduate students


Long term collaborating PhD students


Yushi Hu with Noah Smith

Arijit Ray with Kate Saenko

Former PostDocs
- Wei-Chiu Ma (Faculty @ Cornell) Former masters students - Sho Arora - Ines Chami - Apoorva Dornadula - Oliver Groth - Mayank Kumar - Mona Gandhi - Donsuk Lee Former undergraduate students - Andre Ye - Helena Vasconcelos - Vincent Chen - Shubhang Desai - Omer Gul - Jerry Hong - Khaled Jedoui - Pranav Khadpe - Michelle Lam - Austin Narcomey - Junwon Park - Jihyeon Janel Lee - Joshua Kravitz - Stephanie Chen - Kenji Hata Former PhD mentees - Ankit Vani - Kalyani Marathe - Sebastin Santy - Done He - Jingwei Ji - Siddharth Karamcheti Selected TalksVenue: CVPR 2024 - Computer Vision and Pattern Recognition
Panel: CVPR: past, present, and future Venue: CVPR 2020 - Computer Vision and Pattern Recognition
Title: Compositionally in Computer Vision [slides][video][workshop] Venue: CVPR 2020 - Computer Vision and Pattern Recognition
Title: Dense Captioning Events in Videos [slides][video][workshop] Venue: ECCV 2016 - European Conference on Computer Vision
Title: Visual Relationship Detection with Language Priors [pdf][project][slides][poster][video] Venue: CHI 2016 - Conference on Human Factors in Computer Systems
Title: Embracing Error to Enable Rapid Crowdsourcing [pdf][slides] MISCELLANEOUS
Trailer for a documentary
Venue: PBS NOVA Title: Can we build a brain? Year: 2018 Complete documentary
Venue: PBS NOVA Title: Can we build a brain? Year: 2018 |